Sentence Embedding
Sentence Embedding
如果需要判断句子与句子之间的相似度,仅使用上述的词向量方法显然是不行的,所以如何获得句向量也是十分重要。句向量代表了整句话的语义信息,可以帮助机器理解上下文,意图及其它重要信息。
获得句向量的方法可以归为加权平均法和模型法两大类,下面分别给出这两大类中的具体方法:
加权平均法
加权平均法用了一种比较朴素的思想,利用句子中每个词的词向量加权来求得句向量,下面给出具体的方法:
累加求平均
直接对句子中每个词的词向量累加后求平均作为句向量。
TF-IDF 加权求平均
利用TF-IDF值对句子中每个词的词向量进行加权后求平均。
幂均值(Power Mean)加权平均
幂均值加权平均的全称为 Concatenated Power Mean Word Embeddings,即级联的幂均值词向量方法,其论文链接在参考[1]中给出,该方法的核心是幂均值和级联。
幂均值:
上式中,$n$ 为句子中词的个数,$x$ 为词向量。当 $p=1$ 时,上式即为简单的加权平均法,当 $p=+∞$ 时,相当于取每个词向量各维度的最大值,当 $p=-∞$ 时,相当于取每个词向量各维度的最小值。
级联:
考虑到不同的预训练词向量能够学习到不同的信息,论文中使用了四种不同的词向量:GloVe, Word2Vec, Attract-Repel 和 MorphSpecialized。为了能够利用不同的信息,该方法对这四种词向量进行了拼接,如下所示:
论文中最后构造的词向量维度是 $4 \ast 3 \ast 300 = 3600$,其中$4$表示使用四种不同的词向量,$3$表示 $p$ 取值为 $\{-\infty, 1, +\infty\}$.
SIF(smooth inverse frequency)加权平均
SIF 【论文和代码】是一种简单且效果很好的获取句向量的加权方法,其在语义文本相似性任务上的表现甚至超过深度学习技术,比如 InferSent等。但是,在分类任务方面,SIF稍微落后于其它深度学习模型。这可能是因为加权平均的方法并不能提供足够复杂的表示来解决诸如情感分析之类的任务。(参考[2]).
SIF 加权平均法的计算步骤如下所示:
- 计算语料库中所有词的词频;
- 给定超参数 $a$,通常取值为 $1e-3\sim1e-3$,计算词向量的权重:$a/(a+p(w))$,其中 $p(w)$ 为词频;
- 使用SVD计算句向量矩阵的第一主成分 $u$,让每个句向量减去它在 $u$ (单位向量)上的矢量投影[移除所有句子的共有信息,因此保留下来的句子向量更能够表示其本身与其它句子向量之间的距离]。

模型法
模型法主要是利用深度网络模型来获得句向量,可以分为无监督、有监督和多任务三大类(参考[3])。
无监督模型法
Skip-Thought Vectors
Skip-Thought Vectors【论文】与 word2vec 中 skip-gram 的训练思想类似,通过一句话来预测其上一句话和下一句话。该模型是典型的 encoder-decoder 结构(GRU-RNN),只不过其有两个decoder,具体网络结构如下所示:

Quick-Thought Vectors
Quick-Thoughts【论文】模型是对 Skip-Thoughts 的优化,其主要优点在于训练速度的提升。Skip-Thoughts 网络结构实质上是生成模型,而且需要训练3个循环神经网络。Quick-Thoughts 则将整个过程当作分类任务来处理,具体网络结构如下所示:
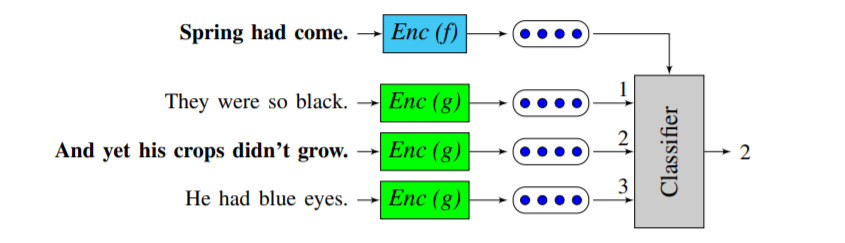
对于一个给定的句子 $s$,判断 $s_{cand} (s_{cand}\in S_{cand})$ 是其上下文的概率为:
上式中,$f$ 和 $g$ 分别为两个不同的 encoder(RNN 网络),$S_{cand}$ 包含一个正例和多个负例(即一个上下文句子和多个非上下文句子),$c$ 是打分函数,论文中将其简单定义为向量的内积,即 $c(u,v)=u^Tv$.
从上文求条件概率的等式中可以看出,该任务的目标函数是希望句子 $s$ 和其上下文句子的向量内积越大越好,反之则越小越好。Quick-Thoughts 训练完成之后,对于下游任务中的任一句子 $s$,通过拼接 $f(s)$ 和 $g(s)$ 计算得出的向量来得到 $s$ 对应的句向量。
Doc2vec 模型
Doc2vec【论文】是将 word2vec 的概念扩展到句子,段落或整个文章所形成的嵌入模型,借鉴 word2vec 中 CBOW 和 Skip-gram 的思想,其有两种添加句向量到模型中的方法。
PV-DM(Distributed Memory version of Paragraph Vector)
该方法与 CBOW 类似,通过上下文预测下一个词。但其在输入层额外添加了该上下文所对应的句向量,具体的网络结构如下所示: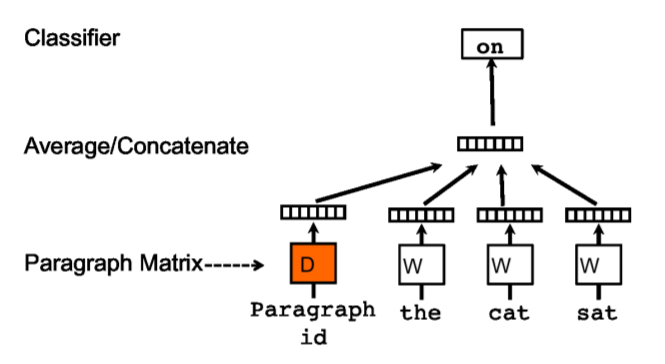
训练结束后,对于现有的文档,可以直接通过网络训练后得到的句向量矩阵查询。而对于一篇新的文档,需要重新将其输入到网络中进行训练,但该过程会冻结模型里的词向量矩阵以及投影层到输出层的权重参数,只需要更新句向量,所以该过程会很快收敛。
PV-DOBW( Distributed Bag of Words version of Paragraph Vector)
该方法与 Skip-gram 类似,通过文档来预测文档内的词。训练时随机从预测文档内采样一些文本片段,然后再从这个片段中采样一个词作为 label,模型借助这一分类任务来训练句向量,具体的网络结构如下所示: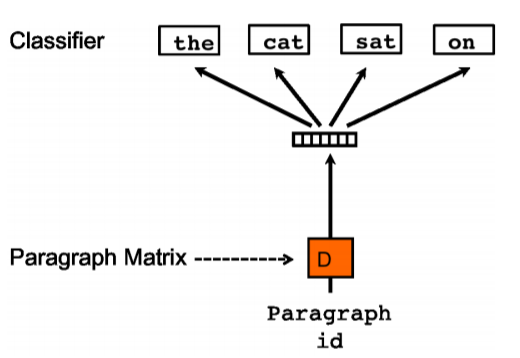
有监督模型法
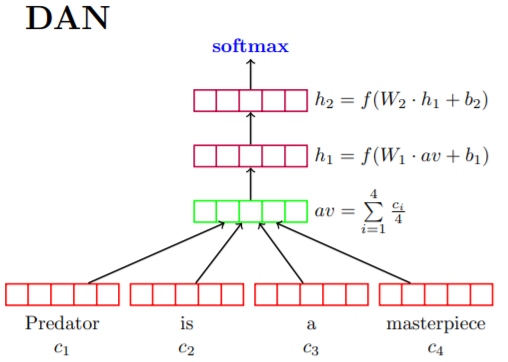
Deep Averaging Networks (DAN)
DAN 模型【论文】的实现方式比较简单和直观,首先将句子中的词向量求平均作为网络的输入嵌入表示,随后使该平均向量经过一个或多个前馈层,最后经过 softmax 层来完成相应的分类任务,具体的网络结构如下所示:
Self-attentive Sentence Embedding
该模型【论文】通过引入 self-attention 机制来得到句向量,之前介绍的方法获得的词向量都是一维的向量表示,而该方法得到的句嵌入是二维的矩阵表示,矩阵的每一行表示对句子不同部分的注意,其网络结构如下所示:
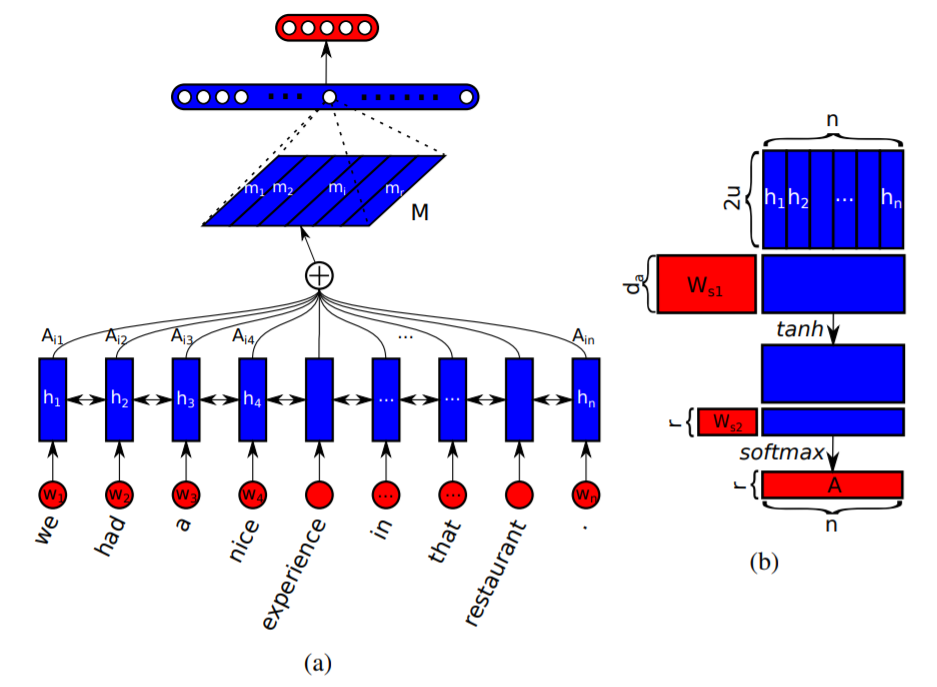
从上图(a)中可知,网络底层结构使用的是 Bi-LSTM,其隐层维度为 $u$,故而 $H\in R^{\,n\times 2u}$。图(b)是计算 self-attention 矩阵 $A$ 的过程
上式中,$W_{s1}\in R^{\,d_a\times 2u}$,$W_{s2}\in R^{\,r\times d_a}$,所以 $A\in R^{\,r\times n}$,最后用 self-attention 矩阵 A 与 隐向量矩阵 $H$ 相乘便可以得到最终的句子嵌入
InferSent
InferSent【论文】是由 Facebook AI Research 提出的一种句嵌入方法,该方法通过训练 Natural Language Inference(NLI) 模型的方式来间接获取句向量,其通用的训练结构如下所示: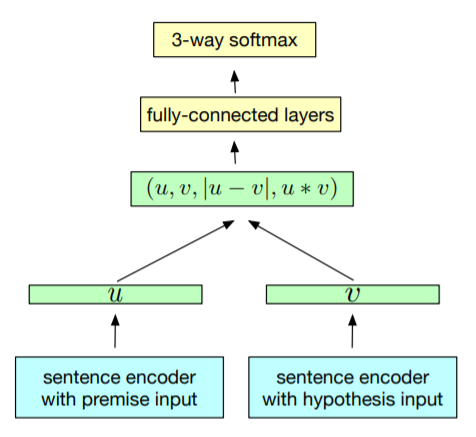
上图中 $u$ 和 $v$ 权值共享, $u$ 和 $v$ 也是我们最终需要获得的句向量。这个框架最底层的 sentence encoder 便是最终要获取的句向量提取器。
在训练过程中,premise 和 hypothesis 的句子嵌入以及它们按元素乘积和按元素求差的结果被级联在一起,拼接后的混合语义特征向量被送入多个全连接层,最后以3分类的softmax层(类别为entailment 蕴含,contradiction 矛盾,neutral中立)结束。
读到这里,细心的你应该会发现还有一个重要的问题没有解决,那就是 sentence encoder 的结构还没有确定。论文作者对比了7种不同的 sentence encoder,主要包括 RNN 与 CNN,其中 RNN 包括取 LSTM/GRU 最后一个隐状态,Bi-GRU/Bi-LSTM 的 mean/max pooling 以及 self-attention,其中取得最优效果的是 Bi-LSTM + max pooling,下面给出其具体结构:
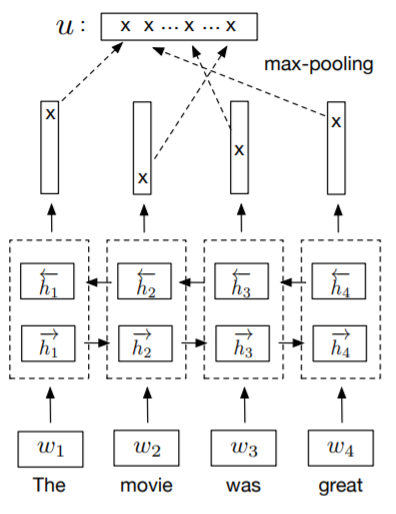
由上图可知,sentence encoder 最终生成的句嵌入是通过将两个 LSTM 网络的输出向量进行级联,随后在每个维度取最大值的方式获得。
Sentence-BERT
Sentence-BERT 这篇【论文】指出 Bert 在处理判断句子之间的相似度问题时所消耗的时间非常巨大(论文中给了一个小例子来阐述),这个问题的产生主要是受限于 Bert 的结构。但直接用 Bert 的输出作为句向量的效果比加权平均的 GloVe 还要差。基于上述问题,论文的作者提出了 Sentence-BERT 方法来获得效果较好的句向量。
SBERT 是在 siamese/triplet 网络结构上对 BERT 的微调,个人觉得其网络结构和 InferSent 的网络结构几乎没有太大的差异,文中 siamese 网络的具体结构如下图所示:
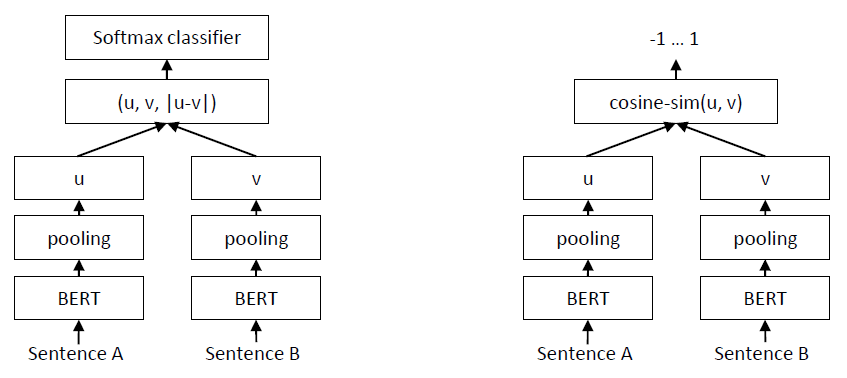
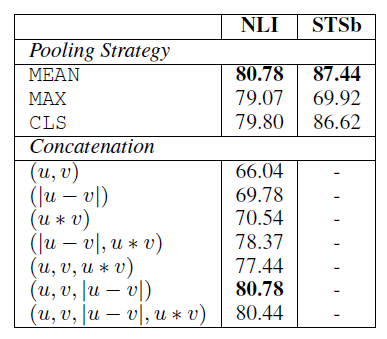
从上图中可以看出,SBERT 和 InferSent 的主要不同点在于 sentence encoder 部分,SBERT 是使用 BERT 网络结构作为其sentence encoder 部分。下表给出其具体的池化策略和级联方式:
多任务学习模型法
Universal Sentence Encoder
Universal Sentence Encoder【论文】是Google 于 2018 年初发布的通用句子编码器,其主要思想是在多个任务上对句子编码器在有监督和无监督的语料库(无监督训练数据包括问答(QA)、维基百科和网页新闻等,有监督训练数据为 SNLI)上进行训练,且编码器参数共享,从而学习出一个通用的句子编码器,这样通用句子编码器生成的句向量便可以应用到不同的 NLP 任务中,比如文本相似性判断,聚类和文本分类等。其具体网络结构如下图所示:
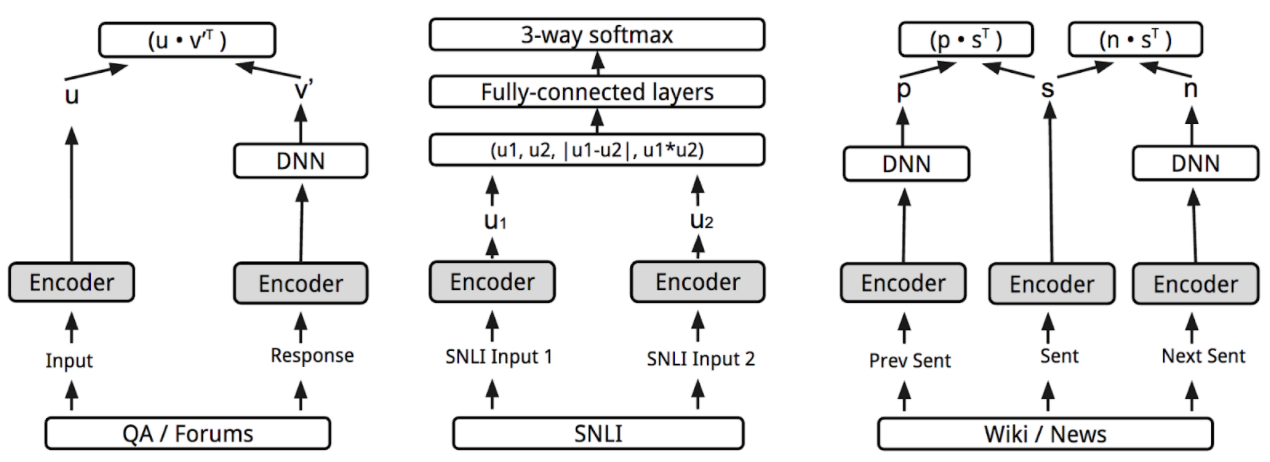
基于准确性和训练速度的折中,文中分别给出了 transformer 和 DAN 两种编码器结构。transformer 编码器有着更好的准确性,对于长句子来说内存开销和计算资源消耗都比较严重,导致计算时间显著增加,但对于短句子来说其计算速度还在可以接受的范围。DAN 编码器相比 transformer 准确性略有降低,但其计算速度快且资源消耗少。
Universal Sentence Encoder 的任务具体介绍以及各任务网络实现的细节可以参考[6],这篇文章用可视化的方法详细介绍了Universal Sentence Encoder,通俗易懂,是很不错的学习资料。
Reference
[1]. Concatenated Power Mean Word Embeddingsas Universal Cross-Lingual Sentence Representations
[2]. How deep does your Sentence Embedding model need to be ?
[3]. 关于句子表征的学习笔记
[4]. From Word Embeddings to Sentence Embeddings — Part 2/3
[5]. Top 4 Sentence Embedding Techniques using Python!
[6]. Universal Sentence Encoder Visually Explained